© 2023 yanghn. All rights reserved. Powered by Obsidian
3.4 softmax 回归
要点
- softmax 函数是为了人为构造概率分布设计出来的
- 交叉熵损失计算分布之间差异,其实和 KL 散度等价
1. 分类问题的独热编码
分类问题本身就是不连续的,直接用离散变量会导致损失函数不可导。统计学家很早以前就发明了一种表示分类数据的简单方法:独热编码(one-hot encoding)。独热编码是一个向量,它的分量和类别一样多。类别对应的分量设置为1,其他所有分量设置为0。在我们的例子中,标签
2. 网络架构
我们可以用神经网络图来描述这个计算过程。与线性回归一样,softmax 回归也是一个单层神经网络。由于计算每个输出
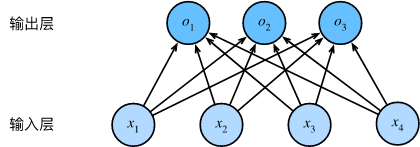
3. softmax 运算
实际上全连接层依旧是个线性模型,为了和
注意
- 是一个向量到向量的函数
- 这种函数不是唯一的,不像熵定义必须是对数函数
- 单调,连续,光滑,大于 0、是选择它的原因
4. 对于多样本的矢量化
为了提高计算效率并且充分利用GPU,我们通常会对小批量样本的数据执行矢量计算。softmax回归的矢量计算表达式为:
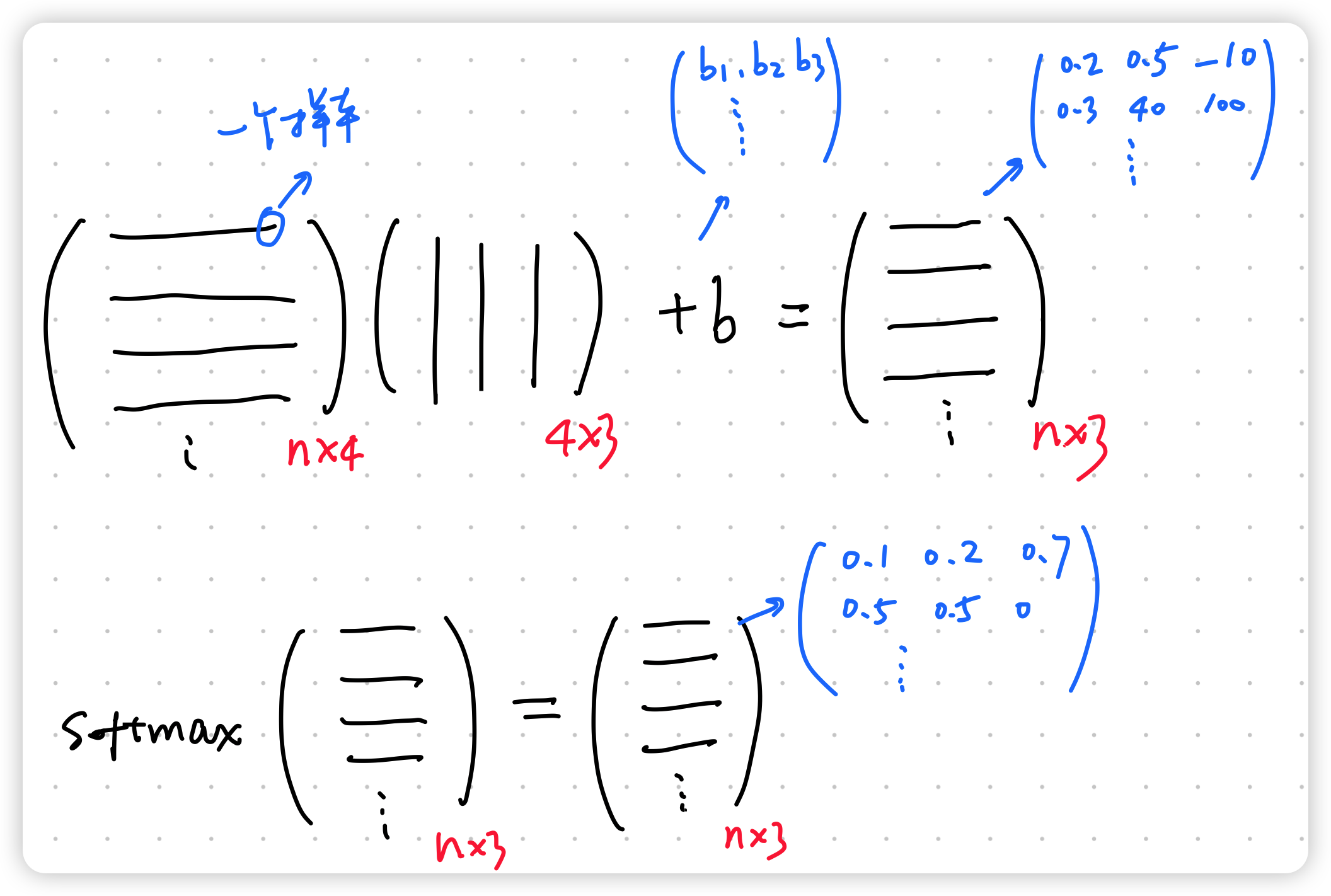
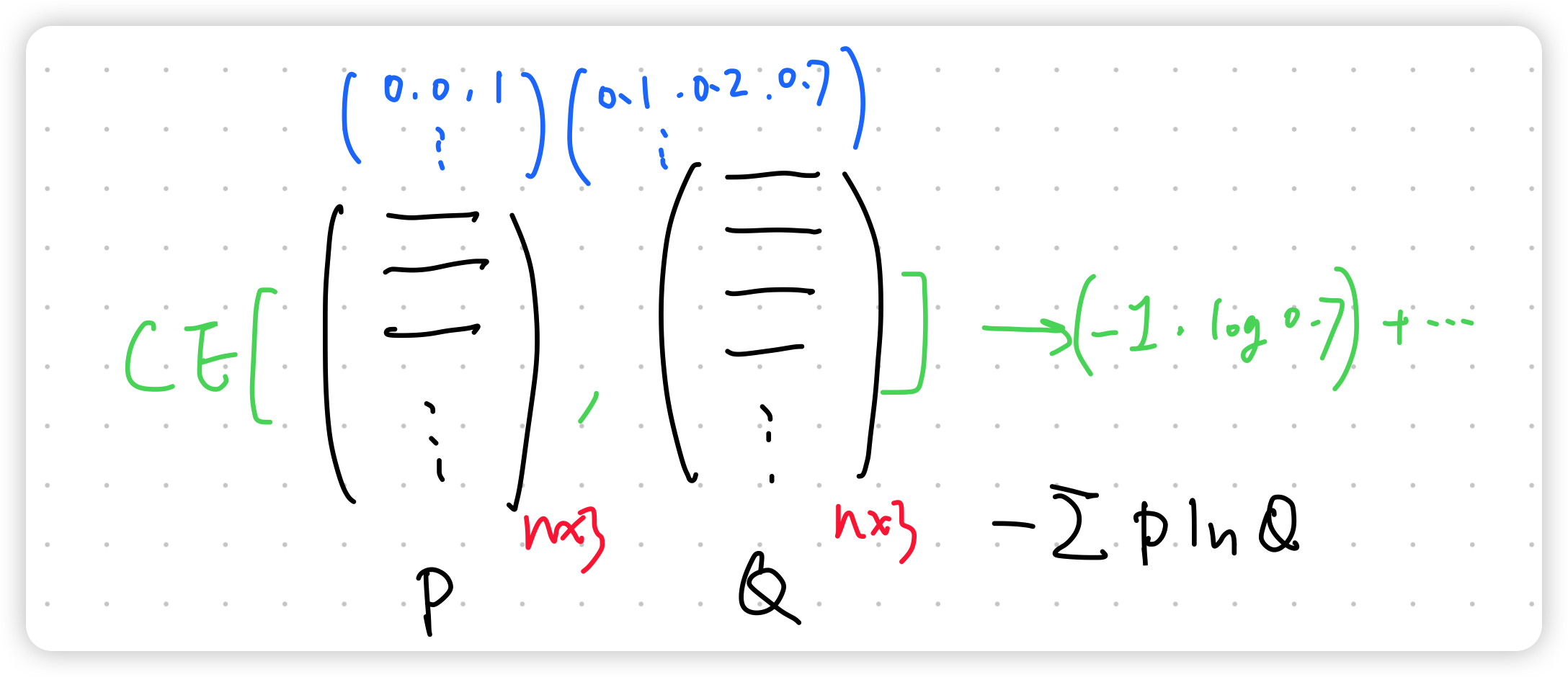
5. 损失函数:交叉熵
最后其实就是分布的差异,交叉熵等价于计算 KL 散度(信息熵(information entropy)#^17aaeb),示意图如下所示: